stanford dogs 분석 및 학습하기
import numpy as np
import os
import cv2
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import models, layers
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import regularizers
stanford dogs 데이터 셋 다운
Stanford Dogs Dataset
Over 20,000 images of 120 dog breeds
www.kaggle.com
해당 데이터 셋을 다운 받으려면 로그인을 해야된다.
데이터셋 제너레이터 만들기
path = "/jupyterNotebook/datasets/stanford_dogs/images/images/Images/"
dogs_name_list = os.listdir(path)
for folder in dogs_name_list:
dir_name = folder
rename = folder.split("-")[1]
os.rename(path+dir_name, path+rename)
dogs_name_list = os.listdir(path)
각 클래스 이름 리스트
dogs_name_list = os.listdir(path)
datagen = ImageDataGenerator(
zca_epsilon=1e-06,
rotation_range=20,
width_shift_range=0.1,
height_shift_range=0.1,
brightness_range=[0.5, 1.5],
shear_range=0.05,
zoom_range=0.2,
fill_mode='nearest',
horizontal_flip=True,
dtype='float32',
validation_split=0.1,# set validation split
)
img_size = (224,224)
batch_size = 240
train_generator = datagen.flow_from_directory(
directory=path,
target_size=img_size,
batch_size= batch_size,
subset='training'
)
Valid 이미지 제너레이터 생성
valid_generator = datagen.flow_from_directory(
directory=path,
target_size=img_size,
batch_size= batch_size,
subset='validation'
)
train_img = next(iter(train_generator))
print(train_img[0].shape)
print(train_img[1].shape)
(240, 224, 224, 3)
(240, 120)
dogs_name_dict = {}
for key, name in enumerate(train_generator.class_indices):
dogs_name_dict[key] = name
plt.figure()
for i in range(8):
plt.subplot(2,4,i+1)
num = np.random.randint(0,len(dogs_name_list))
plt.imshow((train_img[0][num]).astype("uint8"))
plt.title(dogs_name_dict[np.argmax((train_img[1][num]))])
plt.axis("off")
plt.show()
데이터 전처리
Batch크기 데이터셋의 값 분포(히스토그램)
plt.hist(x=train_img[0].reshape(-1,),bins=50)
plt.show()

한개 이미지의 값 분포(히스토그램)
num = np.random.randint(0,len(dogs_name_list))
plt.figure(figsize=(8,3))
plt.subplot(1,2,1)
plt.imshow((train_img[0][num]).astype("uint8"))
plt.title(dogs_name_dict[np.argmax((train_img[1][num]))])
plt.axis('off')
plt.subplot(1,2,2)
sns.histplot(x=train_img[0][num].reshape(-1,),bins=50,kde=True)
plt.show()

한개 이미지의 값 -1~1로 정규화
img_normalize = (train_img[0][num] / 127.5) -1
plt.figure(figsize=(10,2))
for i in range(3):
plt.subplot(1,6,2*i+1)
plt.imshow(img_normalize[:,:,i])
plt.title(dogs_name_dict[np.argmax((train_img[1][num]))]+'filter'+str(i))
plt.axis('off')
plt.subplot(1,6,2*i+2)
sns.histplot(x=img_normalize[:,:,i].reshape(-1,),bins=50,kde=True)
plt.axis('off')
plt.show()
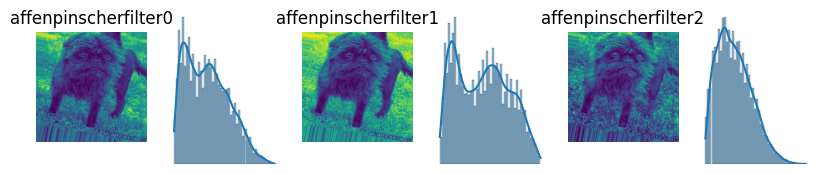
정규화된 서로 다른 이미지 그래프 비교
- 이미지가 밝을 수록 골고루 퍼져있고 반면 이미지가 어두울 수록 -1.0쪽으로 쏠린다.
plt.figure(figsize=(10,5))
for i in range(2):
num = np.random.randint(0,len(dogs_name_list))
img_normalize = (train_img[0][num] / 127.5) -1
plt.subplot(2,2,2*i+1)
plt.imshow(img_normalize[:,:,2], vmax=1)
plt.title(dogs_name_dict[np.argmax((train_img[1][num]))])
plt.colorbar()
plt.axis('off')
plt.subplot(2,2,2*i+2)
sns.histplot(x=img_normalize[:,:,2].reshape(-1,),bins=50,kde=True)
plt.show()

모델 만들기
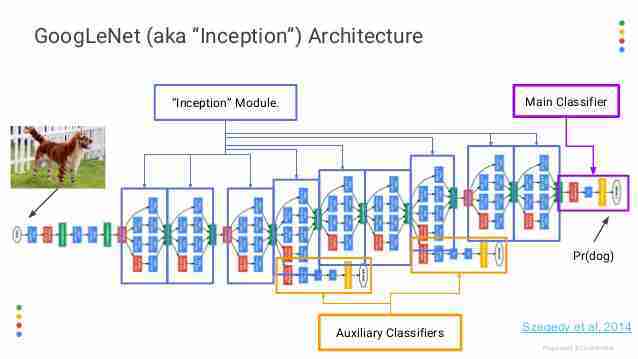
해당 모델은 Inception 네트워크(Google net)을 모방해서 만들었다.
def inception_256(input_image):
conv1 = layers.Conv2D(64,(1,1),kernel_initializer="he_normal",padding="same")(input_image)
conv3 = layers.Conv2D(96,(1,1),kernel_initializer="he_normal",padding="same")(input_image)
conv3 = layers.Conv2D(128,(3,3),kernel_initializer="he_normal",padding="same")(conv3)
conv5 = layers.Conv2D(16,(1,1),kernel_initializer="he_normal",padding="same")(input_image)
conv5 = layers.Conv2D(32,(5,5),kernel_initializer="he_normal",padding="same")(conv5)
convMax = layers.MaxPool2D(pool_size=(3,3),strides=1,padding="same")(input_image)
convMax = layers.Conv2D(32,(1,1),kernel_initializer="he_normal",padding="same")(convMax)
convCat = layers.Concatenate(axis=3)([conv1,conv3,conv5,convMax])
return convCat
def inception_384(input_image):
conv1 = layers.Conv2D(96,(1,1),kernel_initializer="he_normal",padding="same")(input_image)
conv3 = layers.Conv2D(96,(1,1),kernel_initializer="he_normal",padding="same")(input_image)
conv3 = layers.Conv2D(192,(3,3),kernel_initializer="he_normal",padding="same")(conv3)
conv5 = layers.Conv2D(24,(1,1),kernel_initializer="he_normal",padding="same")(input_image)
conv5 = layers.Conv2D(48,(5,5),kernel_initializer="he_normal",padding="same")(conv5)
convMax = layers.MaxPool2D(pool_size=(3,3),strides=1,padding="same")(input_image)
convMax = layers.Conv2D(48,(1,1),kernel_initializer="he_normal",padding="same")(convMax)
convCat = layers.Concatenate(axis=3)([conv1,conv3,conv5,convMax])
return convCat
def inception(input_image):
conv1 = layers.Conv2D(128,(1,1),kernel_initializer="he_normal",padding="same")(input_image)
conv3 = layers.Conv2D(128,(1,1),kernel_initializer="he_normal",padding="same")(input_image)
conv3 = layers.Conv2D(256,(3,3),kernel_initializer="he_normal",padding="same")(conv3)
conv5 = layers.Conv2D(24,(1,1),kernel_initializer="he_normal",padding="same")(input_image)
conv5 = layers.Conv2D(64,(5,5),kernel_initializer="he_normal",padding="same")(conv5)
convMax = layers.MaxPool2D(pool_size=(3,3),strides=1,padding="same")(input_image)
convMax = layers.Conv2D(64,(1,1),kernel_initializer="he_normal",padding="same")(convMax)
convCat = layers.Concatenate(axis=3)([conv1,conv3,conv5,convMax])
return convCat
def inception_720(input_image):
conv1 = layers.Conv2D(180,(1,1),kernel_initializer="he_normal",padding="same")(input_image)
conv3 = layers.Conv2D(180,(1,1),kernel_initializer="he_normal",padding="same")(input_image)
conv3 = layers.Conv2D(360,(3,3),kernel_initializer="he_normal",padding="same")(conv3)
conv5 = layers.Conv2D(45,(1,1),kernel_initializer="he_normal",padding="same")(input_image)
conv5 = layers.Conv2D(90,(5,5),kernel_initializer="he_normal",padding="same")(conv5)
convMax = layers.MaxPool2D(pool_size=(3,3),strides=1,padding="same")(input_image)
convMax = layers.Conv2D(90,(1,1),kernel_initializer="he_normal",padding="same")(convMax)
convCat = layers.Concatenate(axis=3)([conv1,conv3,conv5,convMax])
return convCat
input_image = layers.Input(shape=(224,224,3))
# Feature Extraction
layer0 = layers.Rescaling(scale=1./127.5, offset=-1)(input_image)
layer1 = layers.Conv2D(20,(3,3),kernel_initializer='he_normal',
kernel_regularizer=regularizers.l2())(layer0)
layer1 = layers.BatchNormalization()(layer1)
layer1 = layers.Activation('relu')(layer1)
layer1 = layers.MaxPool2D((2,2))(layer1)
layer2 = layers.Conv2D(64,(2,2),kernel_initializer='he_normal',
kernel_regularizer=regularizers.l2())(layer1)
layer2 = layers.BatchNormalization()(layer2)
layer2 = layers.Activation('relu')(layer2)
layer2 = layers.MaxPool2D((2,2))(layer2)
layer3 = layers.Conv2D(192,(3,3),kernel_initializer='he_normal',
kernel_regularizer=regularizers.l2())(layer2)
layer3 = layers.BatchNormalization()(layer3)
layer3 = layers.Activation('relu')(layer3)
layer3 = layers.MaxPool2D((2,2))(layer3)
# Inception Network
layer4 = inception_256(layer3)
layer4 = layers.BatchNormalization()(layer4)
layer4 = layers.Activation('relu')(layer4)
layer5 = inception_384(layer4)
layer5 = layers.BatchNormalization()(layer5)
layer5 = layers.Activation('relu')(layer5)
layer6 = inception(layer5)
layer6 = layers.BatchNormalization()(layer6)
layer7 = layers.Activation('relu')(layer6)
layer8 = inception(layer7)
layer8 = layers.BatchNormalization()(layer8)
layer8 = layers.Activation('relu')(layer8)
layer9 = inception(layer8)
layer9 = layers.BatchNormalization()(layer9)
layer9 = layers.Activation('relu')(layer9)
layer9 = layers.MaxPool2D((2,2))(layer9)
layer10 = inception_720(layer9)
layer10 = layers.BatchNormalization()(layer10)
layer10 = layers.Activation('relu')(layer10)
layer11 = inception_720(layer10)
layer11 = layers.BatchNormalization()(layer11)
layer11 = layers.Activation('relu')(layer11)
layer12 = inception_720(layer11)
layer12 = layers.BatchNormalization()(layer12)
layer12 = layers.Activation('relu')(layer12)
layer13 = layers.GlobalAveragePooling2D()(layer12)
# Fully Connected Network
layer14 = layers.Dense(512,kernel_initializer='he_normal',
kernel_regularizer=regularizers.l2())(layer13)
layer14 = layers.BatchNormalization()(layer14)
layer14 = layers.Activation('relu')(layer14)
layer14 = layers.Dropout(0.3)(layer14)
layer15 = layers.Dense(256,kernel_initializer='he_normal',
kernel_regularizer=regularizers.l2())(layer14)
layer15 = layers.BatchNormalization()(layer15)
layer15 = layers.Activation('relu')(layer15)
layer15 = layers.Dropout(0.2)(layer15)
layer16 = layers.Dense(256,kernel_initializer='he_normal',
kernel_regularizer=regularizers.l2())(layer15)
layer16 = layers.BatchNormalization()(layer16)
layer16 = layers.Activation('relu')(layer16)
layer16 = layers.Dropout(0.1)(layer16)
layer17 = layers.Dense(120,activation='softmax')(layer16)model = models.Model(inputs = input_image,outputs=layer17)
model.summary()
tf.keras.utils.plot_model(model,show_shapes=True)
GPU 확인
! nvidia-smi
Wed Jun 22 12:19:31 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.73.05 Driver Version: 510.73.05 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | N/A |
| 0% 31C P8 19W / 350W | 22732MiB / 24576MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
학습 설정
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=['accuracy']
)
학습 실행
history = model.fit(train_generator,epochs=200,validation_data=valid_generator)
hist = history.history
학습 결과 그래프로 표현
plt.plot(hist['loss'],label='loss')
plt.plot(hist['val_loss'],label='val_loss')
plt.legend()
plt.show()

plt.plot(hist['accuracy'],label='accuracy')
plt.plot(hist['val_accuracy'],label='val_accuracy')
plt.legend()
plt.show()

임의 배치 valid 데이터로 평가 및 예측 확인
valid_img = next(iter(valid_generator))
model.evaluate(valid_img[0],valid_img[1])
8/8 [==============================] - 0s 19ms/step - loss: 2.9898 - accuracy: 0.4375
[2.989826202392578, 0.4375]num = np.random.randint(0,batch_size)
plt.imshow(valid_img[0][num].astype('uint8'))
plt.title(dogs_name_dict[np.argmax(valid_img[1][num])])
plt.show()
y_pred = model(np.expand_dims(valid_img[0][num],axis=0)).numpy()[0]
names = np.argsort(y_pred)[::-1][:4]
for name in names:
print(y_pred[name],":",dogs_name_dict[name])

0.5803712 : Irish_water_spaniel
0.24352247 : curly
0.060437113 : Bouvier_des_Flandres
0.050474063 : standard_poodle
해당 모델은 특색 있는 강아지를 예측하고 있다. Irish water spaniel는 위의 사진 처럼 파마한 것처럼 전체적으로 털이 갈색이고 복슬하다. Irish water spaniel 다음으로 높은 예측을 한 것은 curly로 curly 또한 파마 처럼 복슬복슬 털이 특징이다.
num = np.random.randint(0,batch_size)
plt.imshow(valid_img[0][num].astype('uint8'))
plt.title(dogs_name_dict[np.argmax(valid_img[1][num])])
plt.show()
y_pred = model(np.expand_dims(valid_img[0][num],axis=0)).numpy()[0]
names = np.argsort(y_pred)[::-1][:4]
for name in names:
print(y_pred[name],":",dogs_name_dict[name])

0.50101376 : Chihuahua
0.33542356 : miniature_pinscher
0.15144889 : toy_terrier
0.006532049 : Italian_greyhound
모델은 비슷한 강아지들은 잘 못 맞춘다. 위의 사진의 정답은 miniatur pinscher이다. 위의 이미지는 miniatur pinscher 이지만, chihuahua(치와와)도 많이 닮았다는 것은 같다.
num = np.random.randint(0,batch_size)
plt.imshow(valid_img[0][num].astype('uint8'))
plt.title(dogs_name_dict[np.argmax(valid_img[1][num])])
plt.show()
y_pred = model(np.expand_dims(valid_img[0][num],axis=0)).numpy()[0]
names = np.argsort(y_pred)[::-1][:4]
for name in names:
print(y_pred[name],":",dogs_name_dict[name])

0.72820383 : Welsh_springer_spaniel
0.10089963 : Brittany_spaniel
0.08779644 : basset
0.054895476 : Blenheim_spaniel
이미지에 강아지 뿐만아니라 다른 대상도 같이 존재 해서 어떤것이 대상인지 구분하기 어려워 하는 것 같다. -> 위치 정보도 같이 학습 해야 될거 같다.
pomeranian(포메라니안) Test 이미지로 오류 분석 하기
흰색 포메라니안 이미지 예측
pomeranian_img_path = '/jupyterNotebook/images/test_images/pomeranian.jpeg'
pomeranian_img =cv2.imread(pomeranian_img_path)
pomeranian_img = cv2.cvtColor(pomeranian_img,cv2.COLOR_BGR2RGB)
pomeranian_img = cv2.resize(pomeranian_img,(224,224))
plt.imshow(pomeranian_img)
plt.axis('off')
plt.show()
y_pred = model(np.expand_dims(pomeranian_img,axis=0)).numpy()[0]
names = np.argsort(y_pred)[::-1][:4]
for name in names:
print(y_pred[name],":",dogs_name_dict[name])
0.75759953 : Samoyed
0.19442149 : Maltese_dog
0.02502904 : Pomeranian
0.015843904 : toy_poodle
갈색 포메라니안 이미지 예측
pomeranian_img_path = '/jupyterNotebook/images/test_images/pomeranian2.jpeg'
pomeranian_img =cv2.imread(pomeranian_img_path)
pomeranian_img = cv2.cvtColor(pomeranian_img,cv2.COLOR_BGR2RGB)
pomeranian_img = cv2.resize(pomeranian_img,(224,224))
plt.imshow(pomeranian_img)
plt.axis('off')
plt.show()
y_pred = model(np.expand_dims(pomeranian_img,axis=0)).numpy()[0]
names = np.argsort(y_pred)[::-1][:4]
for name in names:
print(y_pred[name],":",dogs_name_dict[name])
0.98939496 : Pomeranian
0.0046532797 : keeshond
0.0027974488 : chow
0.0022098701 : Pekinese
흰색 포메라니안은 정답을 예측하지 못하고, 흰색 포메라니안과 비슷한 흰색이고 복슬복슬한 강아지를 예측한다. 반면 갈색 포메라니안은 98% 이상으로 포메라니안을 예측한다. 분석 결과 아마도 포메라니안 학습 이미지가 흰색 보다는 갈색 위주의 포메라니안이 많을 것이다. 한번 포메라니안 학습 이미지를 확인해본다.
포메라니안 학습 이미지 확인하기
pomeranian_path = '/jupyterNotebook/datasets/stanford_dogs/images/images/Images/Pomeranian/'
pomeranian_list = os.listdir(pomeranian_path)
plt.figure(figsize=(30,20))
np.random.shuffle(pomeranian_list) # 이미지들의 순서를 무작위로 섞어 골고루 이미지를 뽑아 올 수 있도록 한다.
for i in range(60):
plt.subplot(6,10,i+1)
img =cv2.imread(pomeranian_path+pomeranian_list[i])
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img = cv2.resize(img,(100,100))
plt.imshow(img)
plt.axis("off")
plt.show()

포메라니안 학습 이미지들을 보면 흰색 또는 검은색 보단 주로 갈색 위주의 포메라니안 들이 많이 보인다는 것을 알 수 있다. 따라서 stanford dogs 이미지는 개 품종을 구분하기에는 충분한 데이터가 모여 있지 않는 것 같다.
Dandie Terrier 이미지의 클래스 활성화 맵 분석
pomeranian_img_path = '/jupyterNotebook/images/test_images/dandie_terrier.jpeg'
pomeranian_img =cv2.imread(pomeranian_img_path)
pomeranian_img = cv2.cvtColor(pomeranian_img,cv2.COLOR_BGR2RGB)
pomeranian_img = cv2.resize(pomeranian_img,(224,224))
img = pomeranian_img.copy()
img = np.expand_dims(img,[0])
img = tf.Variable(img)
preds = model.predict(img.numpy())[0]
temp_conv_layer = model.get_layer('activation_10')
temp_input_model = models.Model(model.input, temp_conv_layer.input)
temp_output_model = models.Model(temp_conv_layer.output, model.output)
with tf.GradientTape() as tape:
temp_input_model_ouput = temp_input_model(img)
temp_input_model_ouput = tf.Variable(temp_input_model_ouput)
temp_output_model_output = temp_output_model(temp_input_model_ouput)[0,np.argmax(preds)]
grads = tape.gradient(temp_output_model_output,temp_input_model_ouput)
pooled_grads = tf.reduce_mean(grads,axis=(0,1,2))
pooled_grads_value = pooled_grads.numpy()
conv_layer_output_value = temp_input_model_ouput[0].numpy()
for i in range(512):
conv_layer_output_value[:,:,i] *= pooled_grads[i]
heatmap = np.mean(conv_layer_output_value,axis=-1)
plt.imshow(heatmap)
plt.show()

heatmap = cv2.resize(heatmap, (pomeranian_img.shape[1],pomeranian_img.shape[0]))
heatmap = np.abs(heatmap)
heatmap_rgb = (heatmap - np.min(heatmap))/(np.max(heatmap) - np.min(heatmap))
# minmax 정규화 -> 0~1로 정규화
heatmap_rgb = np.uint8(heatmap_rgb*255) # RGB포맷(0~255)으로 변경
heatmap = cv2.applyColorMap(heatmap_rgb, cv2.COLORMAP_JET)
superimposed_img = heatmap*0.4 + pomeranian_img
superimposed_img = np.minimum(255,superimposed_img).astype('uint8')
plt.imshow(np.minimum(255,superimposed_img).astype('uint8'))
plt.title("Dandie_terrier")
plt.colorbar()
plt.show()

names = np.argsort(preds)[::-1][:4]
for name in names:
print(preds[name],":",dogs_name_dict[name])
0.9999249 : Dandie_Dinmont
3.9852854e-05 : miniature_schnauzer
1.9835657e-05 : Tibetan_mastiff
8.171563e-06 : Old_English_sheepdog
Dandie_terrier 이미지의 클래스 활성화 맵을 보면 얼굴에 강하게 활성화 되고 있다. 따라서 Dandie_terrier 이미지를 예측할 때 몸통 보다는 얼굴에 많이 반응한다는 것을 알 수 있다.
Top3 클래스 정확도 확인
y_pred_top3 = np.argsort(model(valid_img[0]))[:,::-1][:,:3]
y = np.argmax(valid_img[1],axis=1)
accuracy = 0
for i in range(len(y)):
if(np.sum(y_pred_top3[i] == y[i])):
accuracy +=1
accuracy /=240
print(accuracy)0.6791666666666667Result
- The Mahine accuracy is 43% in Total Valid Image.
- The Machine accuracy is 67% in case top3-class.
- Dogs are difficult to distinguish because they look similar in general.
- When there is a similar dog, the prediction rate is low. ex)keeshond : 0.5545283, Norwegian_elkhound : 0.4246519


- The prediction rate is reduced by the surrounding sculpture.

- The prediction rate is relatively low when other targets take up more space than dogs.

- If the dog's image is not clear, the accuracy is poor.

- Normalization makes it more difficult to distinguish images
- This machine reacts a lot to colors.
- Due to the small size of the image, the ability to distinguish images is relatively poor.(150x150->224*224)
- Data augmentation eliminates the need for a dog, resulting in poor predictive rates.
- There are dog images that are hard to distinguish clearly.(people are also difficult to distinguish the image)
'딥러닝' 카테고리의 다른 글
| GAN개념과 DCGAN 구현 (0) | 2022.07.12 |
|---|---|
| 클래스 활성화의 히트맵 시각화 (0) | 2022.06.23 |
| 컨브넷 필터 시각화 (0) | 2022.06.23 |
| Cat vs Dog 분류 모델 만들기 (0) | 2022.06.18 |
| Keras.1 Modeling (0) | 2022.06.18 |



